創作+機械学習 Advent Calendar 2022 結果発表
昨年末に創作+機械学習 Advent Calendar 2022を開催しました。 今年は13記事の投稿がありました。ご参加いただいた皆様ありがとうございました。
優秀賞の発表
記事を投稿していただいた10名を対象に1/3〜1/10の期間で投票を行いました。 主催者の記事を除く7本の記事の記事の中から、良いと思った記事に1人3票投票していていただきました。投票へのご協力ありがとうございました。
受賞対象の記事は以下の通りです。
最優秀賞
優秀賞
- 音楽生成AIを利活用した即興演奏の実践 - skies's blog(brightwaltzさん・7票)
佳作
- [nijijourney] イラスト生成呪文 ベストプラクティス - Qiita(imenurokさん・4票)
- 拡散モデルに言語創作をしてほしいなぁ - hsjoihs’s diary(hsjoihsさん・4票)
最優秀賞には2万円、優秀賞には1万円、佳作には5000円が授与されます。 3位までを優秀賞とする予定でしたが、3位の得票数が同じだったため優秀賞の賞金を二分して佳作という扱いにしました。
また、今回は参加者が少なかったため審査員特別賞の代わりに参加者全員に参加賞を授与することにしました。参加賞の賞金は2000円です。 受賞者の皆様には近日中に賞金の受け取り方法について個別に連絡します。

全体所感(midzさん)
今回は前回と比べると、「モデルを構築した話」よりは、「既存の機械学習サービスをどのように創作に応用するかの方法論」の方が全体的に多かったように感じられます。
特にテキストから画像を生成するサービスが次々と登場し、情勢を追うだけでも大変になった年であったように感じます。
創作に機械学習を応用することが当たり前になる時代に突入しつつあり、そのこと自体は良いことですが、開発競争が激化したために、個人開発で行えることの余地が少なくなってしまったデメリットもあるように感じます。
最優秀賞のLWさんは、機械学習で生成した絵を小説の挿絵として使う方法論を紹介してくださいました。現状制御が難しい画像生成AIを応用する上での妥協点をどう探るべきかを詳しく書いてくださっています。
優秀賞のBrightWaltzさんは、実際に作曲や音楽演奏をしていらっしゃる立場から、音楽生成AIの即興演奏への応用方法を1.AI先行、人後攻、2.人先行、AI後攻、3.AIと人によるリアルタイムインタラクティブ演奏という3つの観点から試した例をご紹介いただきました。
このように、創作をAIに応用することが現実的に可能になった段階では、それぞれの分野のドメイン知識、創作経験が重要だと感じさせてくれた記事であったと思います。
2022年夏頃から一気に創作AIのサービス化競争が熾烈になりました。これまでにAIはブラックボックスだからだめだと散々言われてきましたが、AIが高性能化していくと、人がむしろAIに合わせるような方法を考え出すようになったのが興味深い点でした。これからも創作AIは発展を続けると思いますが、人がAIに寄るのか、AIが人に寄ってくるのか、今後の展開にも目が話せません。今年の年末も楽しみです。
宣伝
このAdvent Calenderは2dmlというDiscordサーバーで企画・運営されました。このサーバーでは創作と機械学習に関する情報交換やイベントの開催を行っています。興味がある方は是非ご参加ください。
招待リンク: https://discord.gg/jQNXjkrqGU
以上です。創作+機械学習 Advent Calendar 2022 にご参加いただいた皆様ありがとうございました。2023年もよろしくお願いします。
姿勢推定を用いたキャラクター画像検索
この記事は創作+機械学習 Advent Calendar 2022の1日目です。
はじめに
去年のAdvent Calendarから一年が経ち、再びAdvent Calendarの季節がやってきました。毎年のことながら時間が流れるのは早いものです。
2022年には拡散モデルを用いた画像生成AIが大発展を遂げました。2015年に話題となったDCGANによるアニメ画像生成(抹茶さんのツイート・rezoolabさんの記事)とNovelAIの生成画像(pixivをNovelAIで検索した結果)を比較すると、まさに隔世の感があります。AIのべりすとをはじめとする言語モデルの応用も進み、小説投稿サイトでAI支援を利用して生成された小説を見かけることも珍しくなくなってきました。
生成モデルが進展した一方、今年は機械学習の訓練データの扱いを巡る論争が激化した年でもありました。mimicの炎上は記憶に新しいところです。海外ではGoogle Copilotに対する集団訴訟が提起されています。
機械学習の創作への応用が正と負の両面で盛り上がった2022年でした。そんな今年のAdvent Calendarにどのような記事が投稿されるのか楽しみにしています。スペースにはまだまだ空きがありますので興味を持った方は今からでも是非登録してみてください。
姿勢推定を用いたキャラクター画像検索
この記事では姿勢推定を用いたキャラクター画像検索サービスについて紹介します。
画像をアップロードするとDanbooruから似た姿勢の画像を検索できるアプリを作った https://t.co/nBmpnPgqM4 pic.twitter.com/0v5bOaWfH7
— きばん卿 (@kivantium) 2022年10月12日
絵を描く際に類似ポーズのイラストを参考にすることがありますが、イラストをポーズで検索することは難しく、せいぜい「手を上げる イラスト」のようなキーワードで検索することしかできないのが現状です。また、NovelAIが登場した当初、生成画像が学習データに酷似しており、学習データの姿勢を保存して画風を変換するような仕組みになっているのではという疑惑の声が上がっていました。学習元のデータセットから姿勢が似ている画像を検索することができれば学習データとの類似性を判定できる可能性があります。(なお現在はStable Diffusionに独自の改造を施したものであることが判明しています: 公式解説)
そこで、姿勢推定を用いてキャラクター画像を検索できるサービスを開発することにしました。
実装
姿勢推定アルゴリズムにはbizarre-pose-estimatorを利用しています。
このモデルは入力画像に対して25個の特徴点(17個のCOCO keypointsと8個の中間点)を返します。

元論文によると検索対象のデータセットは以下のように構築されています。
正規化された特徴点間の距離を利用することで、並進・回転・拡大・縮小に対して不変の特徴量を得ることができます。特徴点は25個あるので =300次元ベクトルになります。
Hugging Faceへのデプロイ
このモデルはメモリの消費量が多いため、手持ちのサーバーにデプロイすることができませんでした。そこで、Hugging Face上にアプリを構築しました。
このアプリではアップロードされた画像の姿勢に類似したの画像を検索することができます。現在は元論文のレポジトリに付属していたデータセットを検索対象としています。このデータセットはDanbooru上でfull_bodyタグがついた単一キャラクターの画像からなるそうです。
にじさーちへの組み込み (β版)
また、このモデルを利用したポーズ検索機能を我々が開発している画像検索サイトのにじさーちに試験的に実装しています。メモリ容量の関係でアップロード画像の姿勢を推定することができないため、代わりに棒人間を動かして検索するユーザーインターフェースを採用しました。検索対象が6000枚程度なので検索性能はあまりよくありません。 (フロントエンドの実装は@amane_lyricに協力していただきました)

開発に興味のある方は是非pull requestを送ってください。
今後の課題
現在利用しているモデルは全身画像を前提としているため、全身が写っていない画像の姿勢推定を行うことができません。投稿されるイラストの多くは身体の一部が写っていないため、検索対象にできる画像の枚数が限られてしまいます。
また、特徴点間のユークリッド距離を特徴量として用いているためか、検索結果が直感的にいまいち正しくないと感じることが多くあります。人間がより自然に感じる姿勢類似性の基準を考える必要がありそうです。
宣伝
私達が発行している同人誌 Pythia 2.0 に『画像からのアニメキャラクター姿勢推定』という記事が掲載されています。
創作+機械学習 Advent Calendar 2022 を開催します
創作+機械学習 Advent Calendar は参加者の皆様に創作(漫画・アニメ・イラスト・小説・音楽・ゲーム等)と機械学習に関連した記事を投稿していただき、優れた記事を書いた方に賞を贈呈する企画です。
この企画は去年に引き続いての開催となります(去年の告知記事と結果発表)。

ルール
- 参加の意思表示はAdventarに記事公開日を登録することで行います。
- 登録日になったら創作(小説、漫画、アニメ、イラスト、映画、音楽、ゲーム等)と機械学習または統計分析に関連する記事を公開してください。
- 2022年内に記事を公開された方を賞の審査対象とします。記事の公開が年内であれば空き枠に後から登録した場合も審査対象になります。
- 一人で複数の記事を投稿しても問題ありません。カレンダーの枠が埋まった場合は2枚目を作成します。
- 記事の公開が登録日よりも遅れる場合はその旨をAdventarに記載してください。コメントがないまま遅れた場合は主催側の判断で登録を解除する場合があります(その場合も後日再登録することが可能です)
- 2023年1月に参加者の相互投票で優秀賞を決定します。
- 賞に関する連絡を送る場合がありますので、2dml Discordに参加する・Twitterで@kivantiumからのダイレクトメッセージを受信できる状態にする(DM解放またはフォロー)・メールアドレスなどの連絡先を記事中に記載する等の方法で主催者と連絡が取れる状態にしてください。
- 記事を投稿してくださった方にはコミケや技術書典等で出版する同人誌への投稿を後日依頼する可能性があります。
記事の書き方
- 記事の形式は主にブログを想定していますが、動画やスライドなどでも大丈夫です。インターネット上で自由に閲覧できるものであれば形式は問いません。
- 記事の冒頭に創作+機械学習 Advent Calendar 2022 の記事であることを明記してください。
- 記事の言語は日本語または英語が望ましいです。
- 推奨ハッシュタグは #創作機械学習 です
テーマの例
- 画像関係: 画像分類・画像生成・自動着色・モーションキャプチャ・各種イラスト生成AIのテクニックなど
- 言語関係: 小説生成・チャットボットなど
- 音声関係: 音楽生成・音声合成・声質変換など
- 統計分析: キャラクター分析・感情分析など
- 創作支援: 機械学習による創作支援ツールの紹介・ツールに支援されて作った作品の紹介など
- その他: データベースの作成・ゲームの自動プレイ・推薦システム・AIを創作に使用するための方法論など
具体的な記事例は去年のAdvent Calendarを参考にしてください。
上に挙げた以外のテーマでももちろん大丈夫です。カレンダーのタイトルは「機械学習」としていますが、実際には人工知能関連の技術を幅広く対象にします。何が人工知能技術なのかについては人工知能学会のAIマップを参考にしてください。

未完成のものやアイデア段階の記事も歓迎します。「〜というデータを集めて、自動で〜する機械学習モデルを作りたいと思っています。協力者募集」みたいな感じでも問題ありません。
賞について
以下の賞を用意しています。審査員特別賞を提供してくださる方がいらっしゃったら連絡してください。
- 最優秀賞 (1名) 賞金20000円
- 優秀賞(2〜3名)賞金10000円
- 佳作(若干名)
- 審査員特別賞
賞金はAmazonギフトカードでの支払いを予定していますが、希望があれば他の方法にも柔軟に対応します。 皆様の投稿をお待ちしております。
宣伝
Discordサーバー
創作と機械学習に関するDiscordサーバー 2dml があるので、興味がある方はご参加ください。このAdvent Calendarの運営についてもこのDiscordで議論しています
招待リンク: https://discord.gg/jQNXjkrqGU
同人誌
去年のAdvent Calendar参加者を中心に執筆した同人誌をBoothで販売しています。売上はAdvent Calendarの賞金として活用させていただきます。
LT会
2022年11月5日に創作AIをテーマにしたLT会を実施します。詳細はconnpassをご覧ください。
3Dプリンター KP3S を買った
最近研究室に導入された3Dプリンターを見ていたら私物の3Dプリンターが欲しくなったのでKingroonのKP3Sを購入しました。テスト印刷が無事に成功したのでここまでの記録を残しておきます。
機種選定
家庭用に販売されている3Dプリンターは熱溶解積層方式 (FDM) と光造形方式の二種類が主流です。
- 熱溶解積層方式 ― 溶かした材料を積み重ねてプリントする方式。取扱いが比較的簡単らしい
- 光造形方式 ― 液体樹脂に紫外線を当てて固める方式。精度が高く仕上がりもきれいだが、二次硬化や廃液処理が面倒らしい。
みっきーさんのPhoton Mono 4K 光造形3Dプリンターを導入したを読んで光造形方式のPhoton Mono 4Kを購入することも検討したのですが、廃液処理が面倒そうだったのでFDM方式の機種を選ぶことにしました。

FDM方式の低価格帯モデルではEnder 3の人気が高いようでしたが、レビューによると組み立てに時間が掛かり調整も難しいという評判でした。

他の機種を探して「3Dプリンター 家庭用 おすすめ」などと検索してみたところ、KP3Sという機種が見つかりました。KP3Sは組み立てが簡単という評判で、日本語圏のユーザーも比較的多くいるようでした。特にKINGROON KP3S INFOというページにたくさんの情報が掲載されていたのが安心材料になり、購入を決定しました。

開封の儀
Amazonで注文しました。




組み立て
組み立てが簡単という前評判の通り、マニュアルは1ページだけでした。
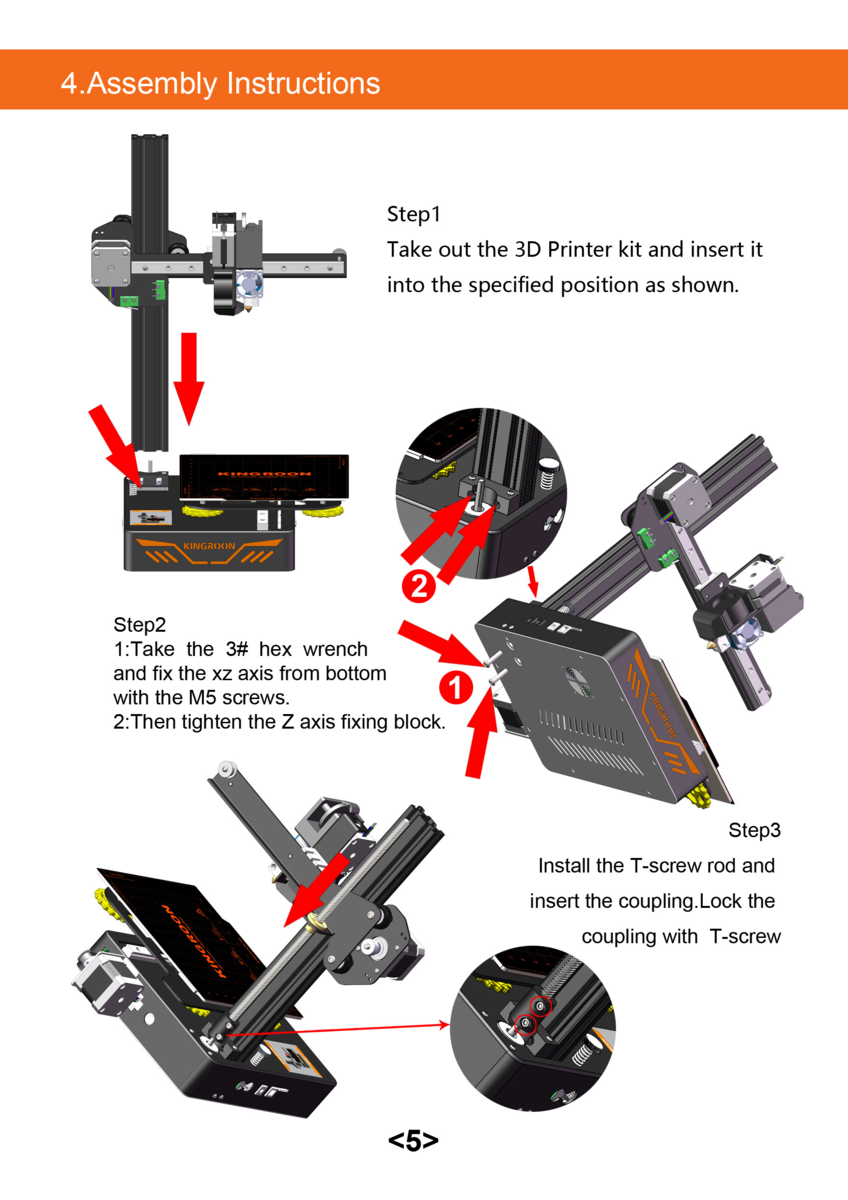
先人たちのブログに「組み立ては簡単で特に書くことがない」などと書いてあったので特に何も見ずに組み立てようとしたのですが、Step 2-2の "Then tighten the Z axis fixing block" を具体的にどうすればいいのか分からずそこで詰まってしまいました。"Z axis Screw" と書かれた袋にはネジと角型のナットのようなものが入っているのですが、図を見てもナットが書かれていないのです。
検索して出てきたFraxinus 01 - KINGROON KP3Sを購入してみた - まず分解。の説明に従って、Step 1の前にネジでナットを留めておき、その上からZ軸を差し込みました。


このZ軸固定方法は分かりにくいので他のブログで言及されていても良さそうなものですが、海外の動画などを見ても先ほどのブログ以外の言及が見当たりませんでした。状況証拠からすると、この角型ナットは古いバージョンでは存在しないんだと思います。
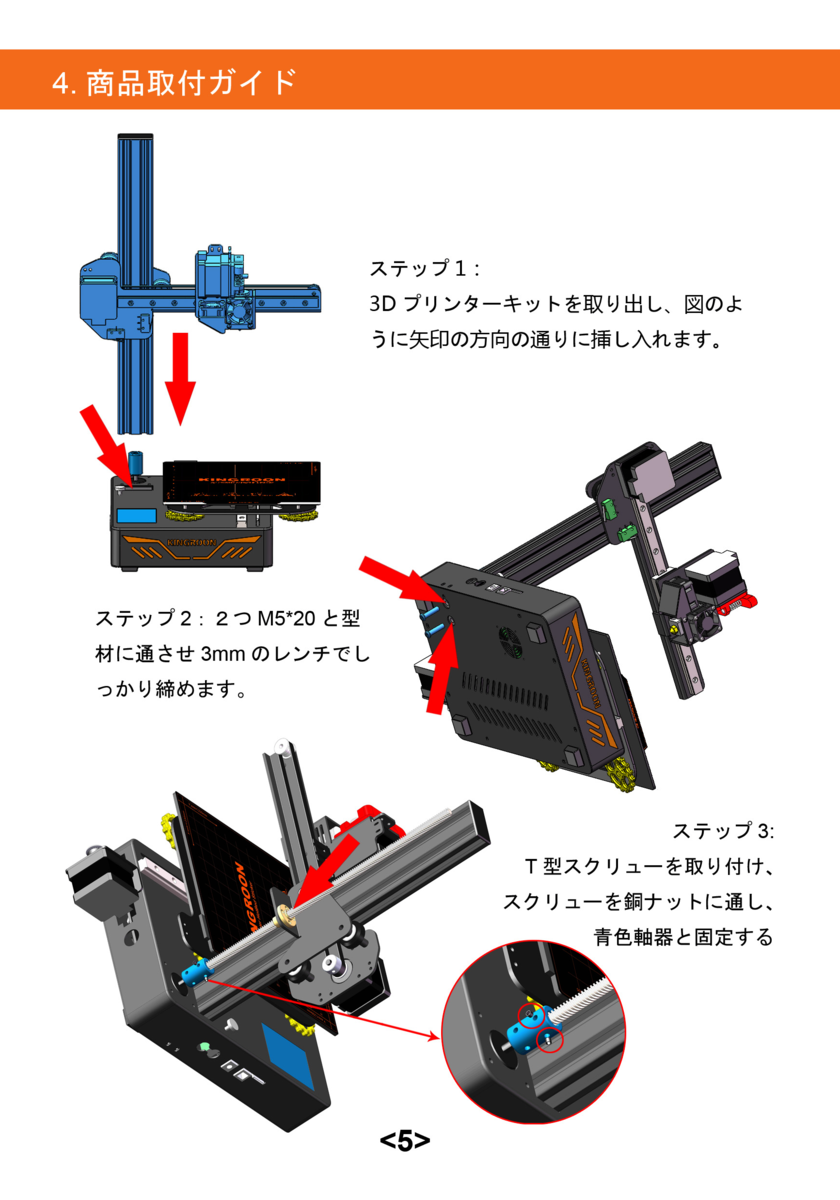
公式の動画でも言及がありません。
ちなみに、この動画ではマニュアルに書いてないことも説明されているので組み立てる前に一度見ておいたほうがいいです。ノズルがプレートを傷つけないようにスポンジで挟んでおくことや電源の電圧設定スイッチはマニュアルに書いてあるべきだと思います。私は電源を入れた後にこの動画の存在に気がつきました。
あとはZ軸方向にT-screwを取り付けて電源をつなげば完成です。3ピンコンセントが必要なので注意してください。

レベリング
テスト印刷の前にノズルの位置を正しく設定するレベリング作業を行う必要があります。ノズルがプレートから0.1〜0.2mmの位置に来るように底面の高さを設定してやります。
レベリングは 激安3Dプリンタ Kingroon KP3Sを購入した(後編) - PikaPikaLightと基本的な使い方 – KINGROON KP3S情報を参考にしました。上に貼った公式動画にも説明があります。
大まかな手順は以下の通りです。
- コピー用紙をプレートの上に置いておく
- 本体の Leveling ボタンを押してノズルを所定の位置に移動させる
- 隙間が空いている場合は本体左側の銀色のネジ (Z leveling Nut) を回して高さを大まかに調整する(このとき Move ボタンでノズルを上げる必要がある。ネジはコインを使うと回しやすい)
- 再び Leveling ボタンを押して今度はプレート下側の黄色いネジで四隅の高さを調整する(黄色いネジは最初締めておき後から緩めるようにするとやりやすい)
- コピー用紙を動かすときに抵抗を感じるが動かせないほどではない高さになったらOK(公式動画によれば "The proper distance between the nozzle and the hot bed is: A4 paper can be drawn out, and the paper cannot be pushed in. And there are no scratches on the paper." らしいですが、紙に線が残るかどうかギリギリのところまで狭めたほうが良かったです)
テスト印刷
レベリングが終わったらノズルを予熱し、付属のフィラメントを上の穴から差し込みます。最初はうまく入りませんでしたが、気合いで押し込んでいくとなんとか入りました。白いフィラメントを差し込んでいるのに青い糸状のものが出てきてびっくりしましたが、これは出荷時のテスト印刷に使われたものだと思われます。
フィラメントの挿入が終わったら、付属のSDカードを本体に入れ、 Print ボタンを押して "Food_Clip_Fast.gcode" を選択すると印刷が始まります。
動作確認 pic.twitter.com/yV9bfieaYv
— きばん卿 (@kivantium) 2022年9月26日
レベリングがうまく行っていない場合は一段目の印刷がプレートにうまく定着しなくて糸くずのようになるのでその場合はすぐに中止してレベリングをやり直したほうがいいと思います。
出来上がったものがこちらになります。プレートをはがして取り外しました。

少し糸が伸びてますが、付属のニッパーで切れば特に問題ありませんでした。KP3Sで検索するとZ軸方向の精度が甘いという話が出てきて不安でしたが、今のところ問題なさそうです。(現在売られているTitanなんちゃらというバージョンは以前のものから改良されているらしいのでその辺の事情は変わっているのかもしれません)
3DBenchyの印刷
テストデータの印刷に成功したので、配布されている3Dモデルを印刷する手順を確認するために3DBenchyの印刷を行いました。3DBenchyというのは3Dプリンターのベンチマーク用に設計された船のモデルで、世界で最もプリントされている物体だと言われています。作業はスライサーソフトの導入、KP3Sで3DBency(船)を実際に印刷してみる – ゆるぷとSTLをG-codeに変換 – KINGROON KP3S情報を参考に進めました。
まずは3DBenchyのモデルをダウンロードします。
"Download All Files"でダウンロードしたファイルを解凍すると"3DBenchy.stl"というファイルが入っています。
次にSTL形式の3Dモデルから実際の印刷に使うG-codeを生成するスライサーというソフトをダウンロードします。いくつか種類があるようですが、無料でユーザーの多いUltimaker Curaを選びました。
インストール後最初の起動時にプリンターを聞かれるのでKingroon > KP3Sを選択します。設定を変更したほうがいいという話もありますが、初期設定のままでも大丈夫でした。
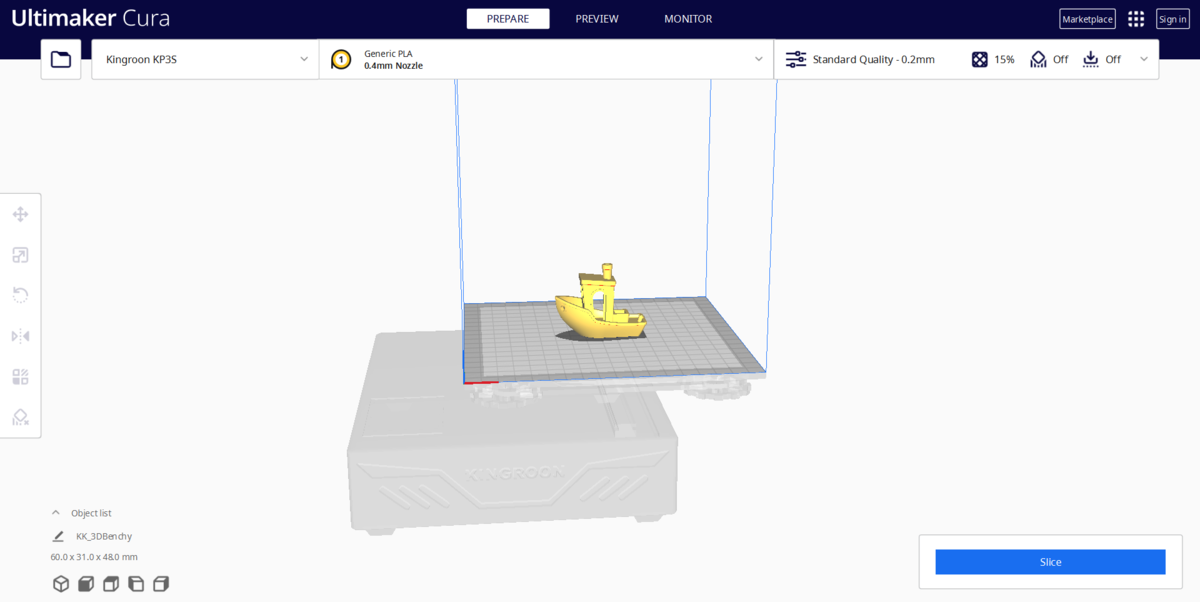
右下のSliceボタンを押し、スライス結果をプレビューしたものがこちら。
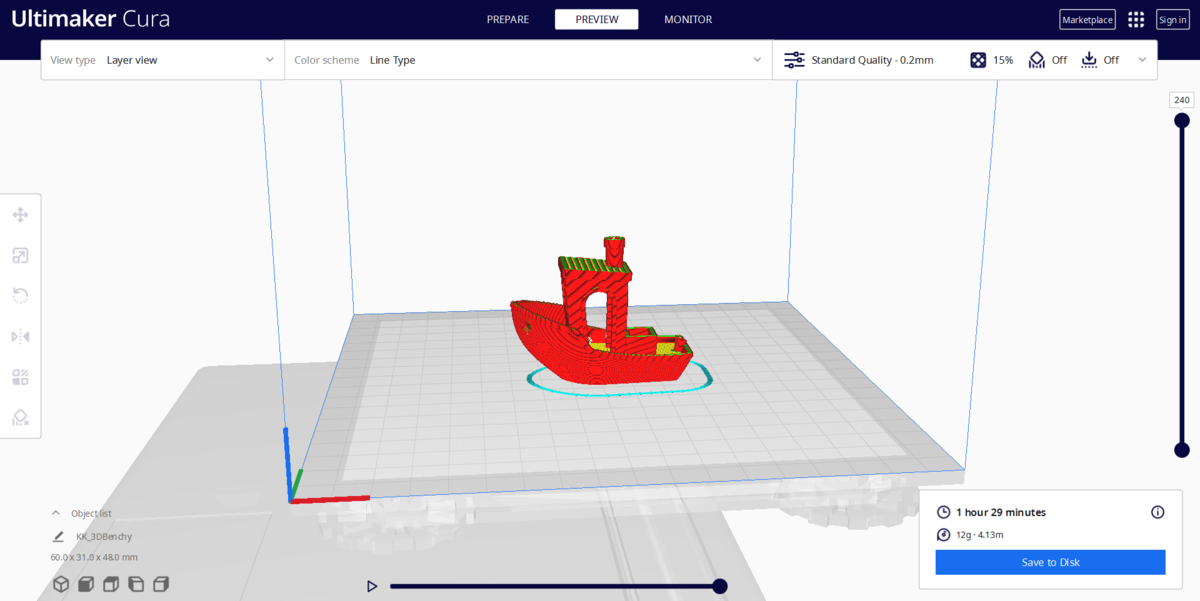
Save To Diskを押してG-codeをDカードに保存したらテストデータと同じように印刷することができます。1時間30分かかりました。


3DBenchyの定性的チェックポイントは船尾のネームプレートの文字が読めないこと以外は大丈夫でした(この項目はhigh-resolution 3D printer向けらしいのでクリアできなくても仕方ないのかもしれない)。定量的チェックポイントも手元の安いノギスで確認できる範囲では問題ありませんでした。
これでワークフローの確認が一通り終わったので、次は自分で設計したモデルを印刷しようと思います。
創作+機械学習 Advent Calendar 2021 結果発表
2021年の年末に創作+機械学習 Advent Calendar 2021というイベントを開催しました。 開始時点での参加者は10人だったのですが、日を追うごとに参加者が増えて最終的には2枚目を作ることになりました。ご参加いただいた皆様、本当にありがとうございました。
優秀賞の発表
ルールに「2022年1月に参加者の相互投票で優秀賞を決定します」と記載した通り、記事を執筆していただいた方々を対象にして1/1〜1/7の期間で投票を行いました。 2021年内に投稿された23本の記事の中から、良いと思った記事に1人3票投票していていただきました。執筆者22名のうち19名から投票がありました。ご協力ありがとうございました。
得票数上位8つの記事を発表します。
最優秀賞
- プレゼン動画を自動的に作成するプログラムの試作(Xiong Jieさん・10票)
優秀賞
- そのキャラを好きになった理由が知りたい(amane_lyricさん・6票)
- 内容にもとづいたアニメ推薦のための Contrastive Learning による埋め込み作成(kirarajumperさん・6票)
佳作
- タダで使える漫画翻訳システムをつくったよ(まっくすさん・5票)
- 櫻木真乃さんと会話する(Kotaro Onishiさん・4票)
- 【イラスト練習法】1年で神絵師になりました(独学編)(ワカドリさん・3票)
- 【2021年】つくよみちゃんと機械学習【音声合成・会話AI】(つくよみちゃんさん・3票)
- 眼鏡っ娘か、眼鏡っ娘ではないか?それが問題だ(KJさん・3票)
最優秀賞には賞金2万円、優秀賞には賞金1万円が授与されます。
審査員特別賞の発表
続いて審査員特別賞です。ルールから審査基準を再掲します。
- @kivantium賞(機械学習の使い方に新しさを感じる記事を書いた方に授与)
- @thetenthart賞(創作支援に役立ちそうな記事を書いた方に授与)
- @xbar_usui賞(機械学習を知らない人でも楽しめる記事を書いた方に授与)
審査員特別賞には賞金5000円が授与されます。各賞に選ばれた記事は次の通りです。
kivantium賞
- 音声認識エンジン『Julius』を使って韻を踏んだフレーズペアを探す(meow_noisyさん)
審査員コメント
音声認識の内部表現から似た音の組を発見して有用な情報を取り出そうとする試みに新しさを感じました。記事に「探したい韻のフレーズを検索する用途に用いるのは必ずしも成功しない」とあり、当初目指していた結果は得られなかったようですが、聞き間違えが生じる仕組みを逆に活用してしまうアイデアの面白さを評価しました。
thetenthart賞
- 【2021年】つくよみちゃんと機械学習【音声合成・会話AI】(つくよみちゃんさん)
審査員コメント
今回Advent Calendarに参加していただいた皆様ありがとうございます。予想よりも多くの方に投稿していただいて、この分野の潜在的な需要の高さを再認識しました。ハイレベルで興味深い記事が多かった中、多くの方に使ってもらえるツールやデータを公開しているという観点で【2021年】つくよみちゃんと機械学習【音声合成・会話AI】をthetenthart賞に選ばさせていただきました。
つくよみちゃんプロジェクトは、キャラクターの商用フリー化・無料でのコーパス公開・音声合成ソフトの公開など、音声合成に関して多岐にわたる大きな貢献をされていて、これからも音声合成界隈を盛り上げてくださるものだと期待しています。
xbar_usui賞
- 架空世界の表意文字用の手書き文字認識を実装したい(part 1) (hsjoihsさん)
- タダで使える漫画翻訳システムをつくったよ(まっくすさん)
審査員コメント
今回、どの作品も読み物としても面白かったので、大変に迷いました。 技術的に、あるいはストーリー的に面白いものは他にもあったのですが、多少主観で「このアイデア面白そう!」という目線で選ばせていただきました。
hsjoihsさんの作品は「架空世界の表意文字を手書き認識させる」という非常にメタというか、ある意味ぶっ飛んでいる創作機械学習でちょっとクラクラきました。 まっくすさんの作品は自分で創作した漫画を、さらに海外の人向けに翻訳するために機械学習を用いたというところに魅力を感じました。
他の方々も、大変面白い作品を投稿いただき、ありがとうございました!

奨励賞の発表
参加者が想定以上に集まったため、事前に決めていた賞に加えて奨励賞を用意しました。奨励賞に選ばれたのは以下の2つです。
- 櫻木真乃さんと会話する(Kotaro Onishiさん)
- 【声質変換+機械学習】Scyclone+Neural Vocoderによる音声の変換(zassouさん)
奨励賞には賞金3000円が授与されます。
アンケート結果
投票と同時にアンケートも行ったのでその結果の一部を紹介します。
投票の際に重視した評価基準を教えてください
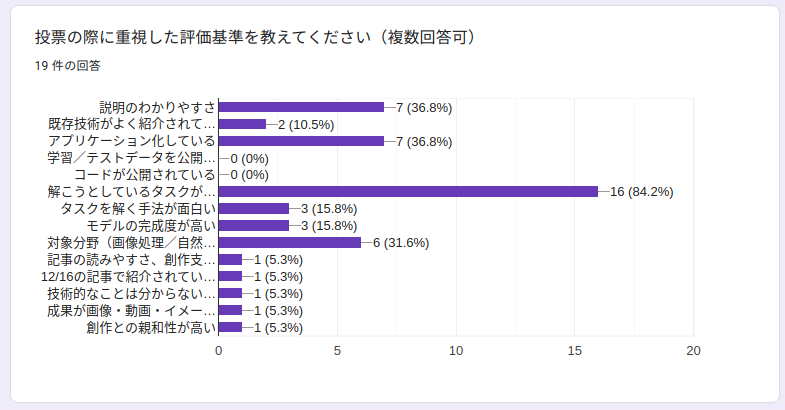
「解こうとしているタスクが面白い (84.2%)」「説明のわかりやすさ (36.8%)」「アプリケーション化している (36.8%)」「対象分野(画像処理/自然言語処理/音声処理など)に興味がある (31.6%)」の順でした。 今年の年末にもAdvent Calendar企画を開催する予定なので、参考にしてください。
今後の活動について
創作機械学習に関連した同人誌を、コミックマーケットや技術書典などの同人誌即売会で出版することを考えています。 現在はアンケートで「とても寄稿したい」を選択した方での執筆を考えておりますが、それ以外にも執筆を望む方がおられましたらTwitter: @thetenthartまでご連絡ください。
内容については基本的に、創作+機械学習(あるいはデータ分析)に関わる記事各々執筆する方向性で考えていますが、執筆者同士で興味の対象がうまく合えば何か統一的なテーマ(ゲーム創作支援など)でかければ良いかとも思っています。
Discordサーバー 2dmlの宣伝
このAdvent Calenderは2dmlというDiscordサーバーで企画・運営されました。このサーバーでは創作と機械学習に関する情報交換やイベントの開催を行っています。興味がある方は是非ご参加ください。
招待リンク: https://discord.gg/jQNXjkrqGU
また、このAdvent Calendarの読者アンケートを実施しておりますのでご協力お願いします。 創作+機械学習 Advent Calendar 2021 読者アンケート
以上です。創作+機械学習 Advent Calendar 2021 にご参加いただいた皆様ありがとうございました。2022年もよろしくお願いします。
はてなブログにAdventarのAdvent Calendarを埋め込む
現在開催中の創作+機械学習 Advent Calendar 2021で、AdventarのAdvent Calendarを埋め込んでいる人がいたのでやり方を調べてみました。
調べてみるとこのAdventarの埋め込み機能はnote向けに実装されている機能のようでした。
- noteに「#アドベントカレンダー」を埋め込めるようになりました!12/25までに記事を書いて、みんなで今年の創作を締めくくりませんか?|note公式|note
- テキスト記事に埋め込みできるサービス一覧 – noteヘルプセンター
- embed機能 開発ガイドライン – noteヘルプセンター
はてなブログはこの埋め込みに対応していないので自力でこの機能を再現する必要があります。 noteが生成したHTMLを読んだところ、次のHTMLを手動で入力すればはてなブログでも同様の埋め込みが実現できることが分かりました。
<iframe src="https://adventar.org/calendars/<カレンダーID>/embed" width="xxx" height="xxx" frameborder="0" loading="lazy"></iframe>
widthとheightは明示的に指定しないとデザインが崩れました。最適な値はよく分かりませんがnoteでは620x362で表示されていたので同じ値を設定しておきます。
創作+機械学習 Advent Calendar 2021を例にすると次のようになります。
<iframe src="https://adventar.org/calendars/6442/embed" width="620" height="362" frameborder="0" loading="lazy"></iframe>
親要素にtext-align: centerを指定すると中央揃えできます(<center>タグでもいいですが既に廃止されているので避けたほうが良いらしいです)
<div style="text-align: center"> <iframe src="https://adventar.org/calendars/6442/embed" width="620" height="362" frameborder="0" loading="lazy"></iframe> </div>
より良い方法があれば教えてください。
銀髪美少女botを作った
この記事は創作+機械学習 Advent Calendar 2021の1日目です。
はじめに
Deep Learningが画像認識コンテストで優勝して以降、機械学習をはじめとする人工知能技術の研究開発は一大ムーブメントとなり、第3次AIブームと呼ばれる状況にあります。このブログでは機械学習を二次元画像に応用した記事を何回か書いてきましたが、機械学習は画像だけではなく音声や言語など様々な分野で応用されています。このAdvent Calendarでは皆様に機械学習の創作への応用事例を紹介していただきます。どんな記事が投稿されるのか楽しみにしています。また、このAdvent Calendarを読んだ方の中に自分でも機械学習をやってみようと思ってくださる方が一人でもいらっしゃれば大変嬉しいです。
12/1時点では10名の方に参加表明をいただいています。参加者の皆様にはこの場を借りてお礼申し上げます。まだまだ枠に余裕がありますので、記事を読んで自分も参加したいと思った方は是非飛び入り参加してみてください。 adventar.org
二次元イラスト収集サイト にじさーち
この記事では現在開発中の二次元イラスト収集サイトにじさーちと、そのデータベースを利用して作った銀髪美少女botを紹介します。にじさーちの開発中のバージョンは記事にしていたのですが、現在のバージョンは記事にしていなかったのでここで紹介しようと思います。
画像の収集
にじさーちはTwitterに投稿された二次元美少女イラストを収集の対象としています。Twitterに毎日投稿される数多くの画像の中から美少女イラストだけを収集するために機械学習を利用しています。収集対象かどうかの判定は2段階で行っています。まず最初にPyTorchでファインチューニングしたモデルをONNXで利用する - kivantium活動日記で紹介したSqueezenetを使ってイラスト or イラストではない の2クラス分類を行います。イラストであると判定された画像に対してさらにIllustration2Vecによってタグ付けを行い、girlを含むタグが付いた画像を美少女イラストと判定して収集対象にしています。全ての画像に対してIllustration2Vecを呼び出すと計算機の負荷が大きかったため、まず軽量なモデルでスクリーニングを行う運用になりました。
どのツイートに対してイラストを含むかの判定を行うかも問題になるのですが、今のところ絵師リストの監視や、フォロワーのRT・いいねなどを対象にしています。お気に入り数が多い画像ツイートをTweet検索を用いて取得する方法なども検討したのですが、イラストを含む画像のヒット率が低かったです。また、最近はシャドウバンによってイラストが検索結果に表示されないことが増えているため、イラストを描く人やイラストをよくRTする人のアカウントを直接監視することが今後より重要になっていくと考えています。なお、pixiv等で知らない絵師を発見した場合は手動で登録することもあります。
画像の表示
こうして収集したイラストはデータベースに登録され、Djangoを用いて構築されたサイトで表示されています。デザインにはBootstrapとMasonryを利用しています。なお、Twitterに投稿されたツイートの表示は、Twitterの開発者利用規約のI-Bで許可されており、 著作権法第四十七条の五で定められた軽微利用の範囲でサムネイル画像等の表示を行っています。
Twitterの利用規約がなかなか厄介で、ツイートを表示するときにはDisplay Requirementsに従う必要があるほか、削除されたツイートの内容を表示してはいけないなどの細かい規定があります。これに従うためにツイートの表示にはTwitterが提供する埋め込み機能を利用し、サムネイル画像のキャッシュなどは持たないようにしているのですが、これによりサイトの動作がかなり重くなっているように感じています。読み込み速度の改善は大きな課題です。

また、現在はIllustration2Vecによるタグ表示が中心になっていますが、Illustration2Vecでタグ付けができるキャラクター数はかなり限られています。同一キャラクターを判定する機械学習モデルを現在開発中なので、これを用いてキャラクターの自動タグ付けを可能にしたいと思っています。
銀髪美少女bot
こうしてTwitterに投稿されたイラストを日々収集していたある日、銀髪美少女好きのフォロイーが「銀髪美少女を自動で収集したい」的な発言をしているのを見かけました。Illustration2Vecに silver hair タグが存在するので、銀髪美少女データベースが既に手元にある状態でした。こうしてにじさーちからスピンオフしたプロジェクトが銀髪美少女botです。
仕組み
にじさーちに登録された画像のうちsilver hairまたはwhite hairタグがついていて500回以上RTされているものを5分に1度ランダムに1つ選んでリツイートしています。銀髪と白髪は非常に似ていてほとんど区別がつかないため、このような運用にしました。また、新着画像がどちらかのタグを含んでいた場合は50いいね以上でリツイートするようにしています。こうすることで過去の名作と直近の作品がバランスよく閲覧できるだろうと考えています。なお、上記のルールを満たさなかった場合でも目視判定して手動でRTすることがあります。

ちなみに、にじさーちはRSS機能を提供しているので特定のタグの新着画像をSlackチャンネルに投稿するなどの使い方もできます。タグ検索したときに出てくる「検索結果: XXXX件」の右側のRSSマークをクリックするとRSSが表示されます。(maidタグのRSSの例)
今後の課題
まず、イラストかそうでないかの判定が甘いことが第一の課題です。よくある誤判定の例としては、コスプレ画像をイラストと判定してしまうミスがあります。コスプレ画像は人間が見ればひと目でイラストでない画像だと見抜くことができるのですが、イラストと似たような色合いになっているため機械学習はうまく区別することができないようです。誤判定した画像を学習データに加えて何度も再学習しているのですが、未だに数多くの誤判定が起こっています。また、そもそも何をイラストと定義するべきかの問題もあります。ソシャゲのスクリーンショットもよく誤ってリツイートしてしまうのですが、キャラクターが描写されているイラストであることには変わりありません。ソシャゲのスクリーンショットを負例に加えて学習すると全体として精度が落ちる懸念があるため、今のところ正例にも負例にも加えずに学習させています。ソシャゲ以外にも、アニメのスクリーンショットや漫画の購入報告・無断転載画像など、イラストではあるのだが収集したくない画像はたくさんあります。コミケのサークルカットを収集するべきかどうかも微妙な問題でした。画像が投稿された文脈を理解して収集するかどうかを判断するのは機械学習には難しいので人手によるスクリーニングに頼っているのが現状です。
髪色の判定も微妙な問題です。同じ髪の色でも光の当たり方によっては別の色で塗られることがあります。銀髪や白髪は特に色が薄いので光の影響を受けやすいように感じています。髪色が微妙な場合は髪色のタグが何もつかないことが多いのですが、極端な場合は別の髪色タグがつくこともあります。
【告知②】GAノベル8月刊『魔女の旅々10 ドラマCD付き限定特装版』メロンブックス限定版が発売されます!! あずーる先生描き下ろし「収納ボックス」が付きます。「魔女旅」6~10巻を収納できる優れもの!!
予約受付中→https://t.co/yADcHUqGUy pic.twitter.com/UNKoA1kSBhblonde hairタグがついている (https://nijisearch.kivantium.net/status/1133960305183039488/)
また、水色の髪と銀髪の区別も難しいと感じています(誤判定されるイラストの例)。設定上の髪色が水色の場合でも、銀髪設定のキャラとほとんど同じ色で塗られることがあるのでキャラごとに設定上の色が何なのかを調べる必要があります。これは画像だけで判定するのが不可能なのでキャラ判定を導入しないと解決できないと考えています。
以上、機械学習を用いてイラストを収集する事例について紹介しました。明日は@amane_lyricさんの「そのキャラを好きになった理由を探る」です。お楽しみに。